Multifunctional ionic liquid: A co-catalyst for electrochemical carbon dioxide reduction reaction
By Dr. Neil Canter, Contributing Editor | TLT Tech Beat April 2024 Interaction of carbon dioxide gas with an ionic liquid above a copper electrode led to the formation of hydrocarbons. HIGHLIGHTS • The challenge […]

Lubricants in Electric vehicles
Introduction The tribological requirements for Electric Vehicles (EVs) and Hybrid Electric Vehicles (HEVs) differ from those of Internal Combustion Engine (ICE) vehicles. In EVs, key concerns include a lubricant’s thermal and electrical properties, copper corrosion, […]



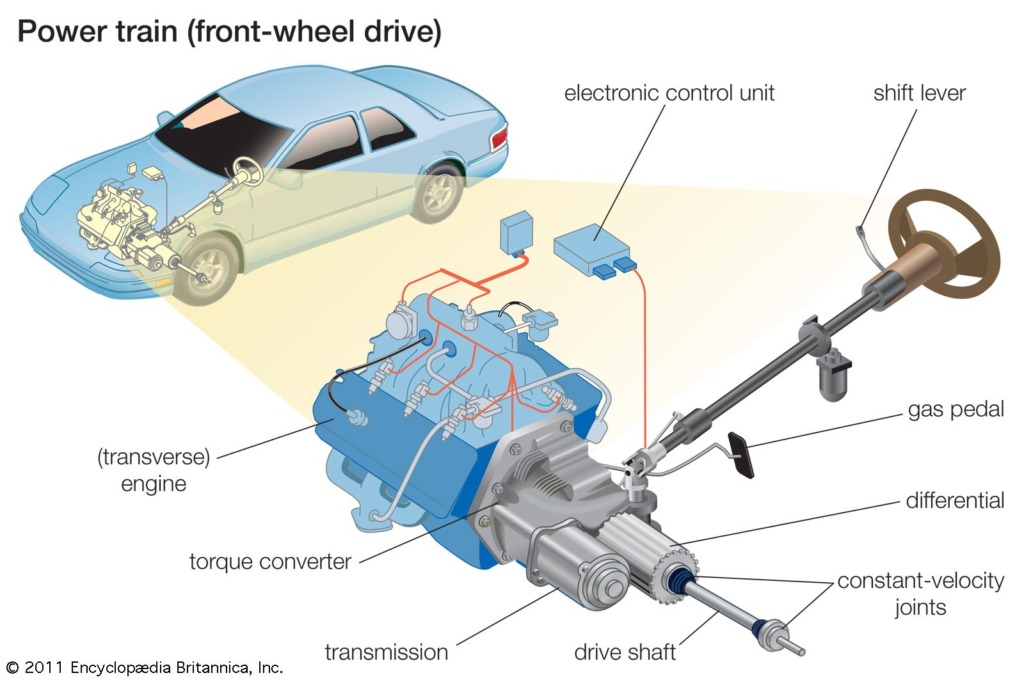
Tribological needs in Electric and hybrid electric vehicles
Introduction Mobility has long been a game-changer for humanity which traces back to the ancient invention of wheels. However, the real revolution began in 1769 with Nicolas Joseph Cugnot’s steam-powered automobile which kicked off curiosity […]


Future Trends in Automobile Tribology
Introduction Future directions in automotive tribology should focus on advancing technical aspects and researching areas related to fuel efficiency, emissions, durability, and the profitability of powertrain systems. Key recommendations include the development of a quantitative […]

Falex Tribology NV Successfully Secures EFRO-VLAIO Project 1948: ‘Vlaams Innovatief Micropitting Labo
Press release (ENG) FOR IMMEDIATE RELEASE **Falex Tribology NV Successfully Secures EFRO-VLAIO Project 1948: ‘Vlaams Innovatief Micropitting Labo’** [Rotselaar, 01/03/2024] – Falex Tribology NV is thrilled to announce its recent success in securing the […]